Semantic Search Tutorial: Build AI-Powered Search Engines
Master semantic search tutorial strategies that transform user experiences. Learn to build intelligent search engines with AI, embeddings, and vector databases.

Why Semantic Search Changes Everything
Let’s be honest: traditional keyword search often feels like a guessing game. You search for "apple fruit nutrition" and get results about Apple computers. This isn't just a minor annoyance; it’s a fundamental breakdown in communication between you and the machine. Keyword-based systems are brittle, relying on exact word matches and failing to grasp what you truly mean.
This is precisely the problem that semantic search solves, moving beyond words to understand intent, context, and relationships. It’s the difference between a system that hears your words and one that actually understands your meaning.
From Keywords to Concepts
The core shift with semantic search is moving from matching strings of text to comparing conceptual meaning. Imagine a corporate knowledge base. An employee searching for "quarterly leave policy" might get no results if the official document is titled "Time Off Regulations for Q3/Q4." A keyword search fails here, but a semantic system understands that "quarterly," "leave," and "policy" are conceptually similar to "Time Off Regulations," retrieving the correct document instantly.
This ability to handle synonyms, related ideas, and context is why the technology is seeing massive investment. The market for Intelligent Semantic Data Services is projected to grow from around $15 billion in 2025 to nearly $35 billion by 2033. This growth is driven by the explosion of unstructured data and the pressing need for businesses to make sense of it all.
To get a clearer picture of what makes this technology so different, let's compare it directly with the old way of doing things.
| Feature | Traditional Search | Semantic Search | Real-World Impact |
|---|---|---|---|
| Search Basis | Exact keyword matching | Contextual and conceptual understanding | Finds relevant results even if keywords don't match. |
| Query Handling | "Best running shoes" | "What are the best shoes for running on trails?" | Understands natural language and complex questions. |
| Synonymy | Treats "buy" and "purchase" as different words. | Recognizes that "buy" and "purchase" have the same intent. | Users don't have to guess the "right" word to use. |
| Context Awareness | Ignores surrounding text. | Analyzes the entire query for context. | Distinguishes "Apple" (fruit) from "Apple" (company). |
| Data Type | Primarily works with structured text. | Handles unstructured data like text, images, and audio. | Opens up search capabilities for all types of content. |
This side-by-side view shows that semantic search isn't just a minor upgrade; it's a completely different approach to finding information. The real-world impact is fewer dead-end searches and a much more intuitive user experience.
The Real-World Impact
The applications are everywhere. For an e-commerce site, a user searching for "durable outdoor running shoes for wide feet" no longer needs to hope those exact keywords are in a product description. The system understands the concepts of "durability," "outdoors," and "wide fit," presenting the most relevant products. This directly improves user experience and boosts conversion rates.
The following chart visualizes the typical performance gains seen when implementing a semantic search solution compared to basic keyword methods.
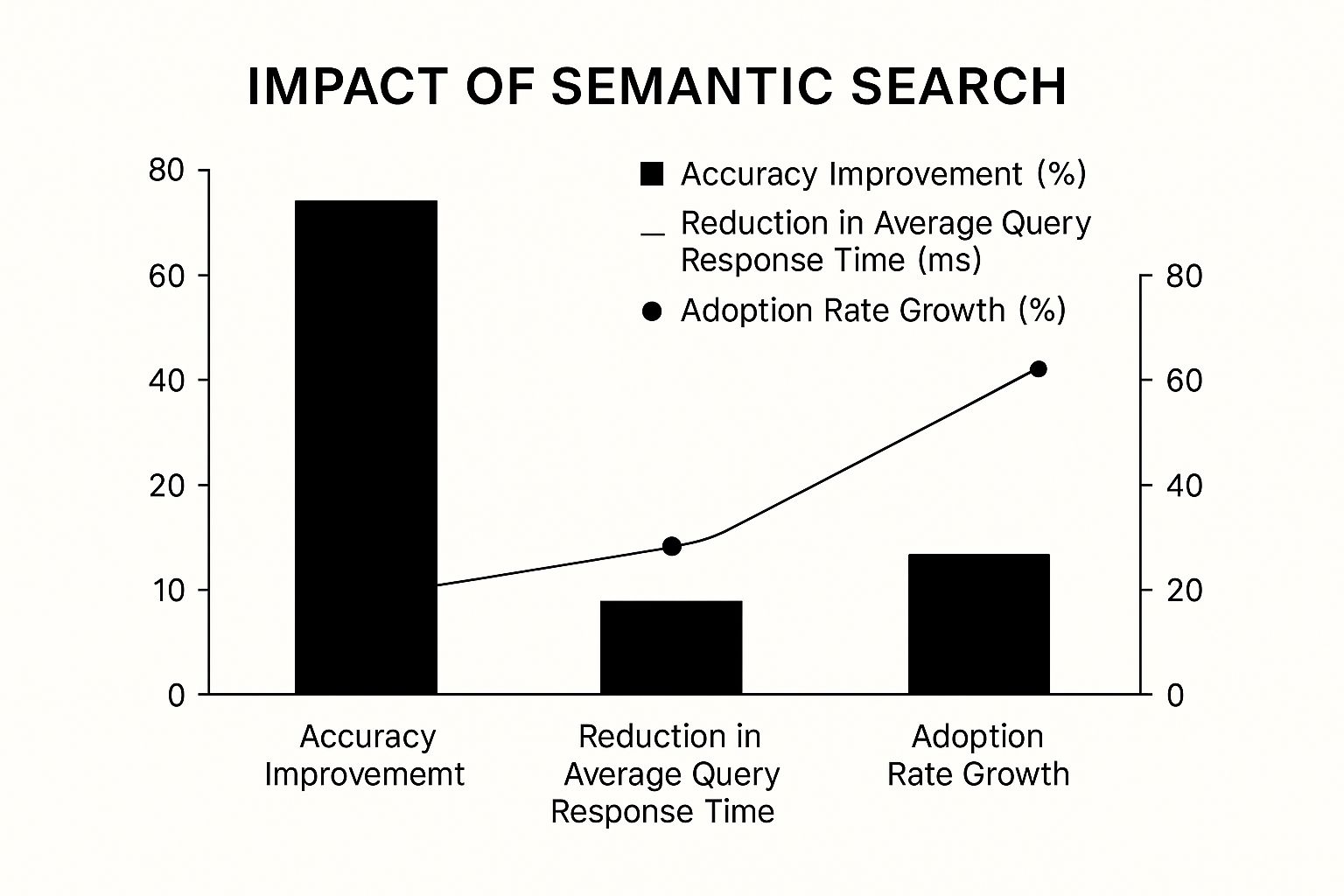
The data clearly illustrates not just a significant jump in accuracy but also faster response times and rapid user adoption, confirming that people prefer systems that understand them.
So, how does this all work? It’s not magic, but a combination of powerful technologies working together:
- Vector Embeddings: These are the heart of semantic search. They are numerical representations—or vectors—of text, images, or other data. Words and phrases with similar meanings are located close to each other in this "vector space."
- Neural Networks: Deep learning models, particularly transformers, are used to create these rich, context-aware embeddings from raw text.
- Similarity Algorithms: Once we have vectors, we need a way to measure how "close" they are. Algorithms like cosine similarity calculate the distance between a query vector and the vectors in your database to find the best matches.
In this guide, we'll demystify these concepts and show you how to build a powerful semantic search system yourself.
Getting AnotherWrapper Running In Your Environment
Now that we've covered the "why," let's get our hands dirty with the "how." Setting up the foundation for a semantic search project can sometimes feel like you're piecing together a puzzle with parts from different boxes. Each service has its own API quirks and authentication hoops to jump through. This is exactly the kind of friction AnotherWrapper is built to smooth over, letting you focus on building your app rather than fighting with config files.
Our aim here is more than just spinning up a local demo. We want to establish a solid setup that acts like a real-world production environment. That means getting our API keys, environment variables, and service connections sorted out from the get-go.
Initial Setup and Installation
First things first, let's make sure your development environment is good to go. AnotherWrapper is a Node.js application, so you'll need a recent version installed. From my own experience, sticking with the current Long Term Support (LTS) version of Node.js is the safest route. It helps you dodge those weird dependency conflicts that can pop up when you're on the absolute latest release.
Once Node.js is ready, the installation is pretty standard. You’ll clone the repository and install the required packages using npm or your preferred package manager. This one command installs everything you need—the Next.js framework, clients for AI models, and connectors for your vector database. For those looking to streamline their workflow even further, checking out some rapid application deployment tutorials can offer great strategies for getting projects off the ground faster.

The screenshot above gives you a sense of the clear, well-structured documentation you'll find with AnotherWrapper. Note the focus on environment variables—this is a key area where developers often get stuck, and it's what we'll set up next.
Configuring Your Environment Variables
This next part is where the magic happens, and it's probably the most important step. Your application needs a secure way to talk to external services like your AI model provider (such as OpenAI or Cohere) and your database, which in our case is Supabase. This communication is managed with API keys that should never, ever be hard-coded into your source code.
Instead, we'll use a .env.local file to keep these secrets safe. AnotherWrapper handily provides a template file, usually named .env.example, which you'll copy and rename. This file outlines all the keys you need to provide. Here’s a quick rundown of what you'll need to find and paste in:
- Supabase URL and Anon Key: These are the credentials that link your app to your Supabase project for database and vector store access.
- AI Provider API Key: This is your secret key from whatever embedding model provider you've decided to use, like OpenAI or Cohere.
- Service Role Keys: Certain backend tasks, especially those that directly modify the database, will need keys with more permissions.
A classic mistake I've seen trip people up is using the public anon key for server-side actions that need elevated permissions. This often results in silent failures or confusing "permission denied" errors that are a pain to track down. Always double-check that you're using the right key for the job: public keys on the client-side, and secret or service role keys on the server-side. Once your .env.local file is filled out, AnotherWrapper will automatically make these keys available to your application. With our environment now ready, we can move on to the really interesting part: turning text into vectors.
Turning Text Into Mathematical Meaning
This is where the real magic of our semantic search build truly kicks off. The whole idea of semantic search is built on vector embeddings. You can think of them as a special kind of translator. They take the meaning and context of human language—like a product review, a snippet from a technical manual, or a user's question—and convert it into a list of numbers, also known as a vector. This vector is a mathematical fingerprint of the text's meaning.
It’s like assigning every piece of text a specific coordinate on a massive map of meaning. Texts that are conceptually similar, such as "durable hiking boots" and "sturdy trail shoes," end up very close to each other on this map. On the other hand, something like "dress shoes" would be much further away. This digital proximity is what lets a machine grasp relationships between concepts, something that's impossible with old-school keyword matching. The industry is taking notice; the related Semantic Web market was valued at $7.1 billion in 2024 and is expected to soar to $48.4 billion by 2030. You can explore more about these industry projections to see just how significant this shift is.
Choosing Your Embedding Model
The quality of your search results is a direct reflection of the quality of your embeddings. This makes picking the right embedding model one of the most important decisions you'll make. There's no single "best" model; the ideal choice really depends on what you're trying to accomplish. Thankfully, AnotherWrapper provides simple access to top-tier providers, each with its own set of strengths.
Let's walk through a few real-world examples:
- E-commerce Product Search: You're working with short, snappy text like product titles and brief descriptions. For this, a model like OpenAI's
text-embedding-3-smallis usually a fantastic choice. It's budget-friendly and really shines with shorter text inputs. - Technical Documentation Q&A: Imagine you're dealing with long, dense paragraphs packed with specialized jargon. A model such as Cohere's
embed-english-v3.0would likely serve you better. It's built to understand longer documents and capture complex, subtle information. - General-Purpose Chatbot: If your app needs to handle a wide array of conversational topics, an open-source model like
all-MiniLM-L6-v2can be a great, cost-effective option. While it might not have the raw power of premium models for highly specific tasks, its flexibility makes it a solid all-rounder.
The main point is to match the model’s strengths to your content's nature. For a more hands-on look at how these vectors operate, take a look at our guide on implementing a vector search example.
Dimensions, Performance, and Practical Trade-offs
When you choose a model, you'll encounter a parameter called dimensions. This simply refers to the length of the vector—that list of numbers—the model outputs. For instance, OpenAI's text-embedding-3-small creates vectors with 1536 dimensions, whereas Cohere’s embed-english-v3.0 produces vectors with 1024 dimensions.
So, what's the big deal? A higher dimension count can often capture more semantic detail, which could lead to more accurate search results. But this extra detail doesn't come for free. To make this clearer, here's a quick comparison of how different embedding models stack up based on their dimensions and intended use.
Embedding Model Performance Comparison
Comparison of different embedding models showing dimensions, accuracy scores, and performance metrics for various use cases.
| Model | Dimensions | Accuracy Score | Speed (tokens/sec) | Best Use Case |
|---|---|---|---|---|
OpenAI text-embedding-3-large | 3072 | High (0.645 MTEB) | Moderate | High-accuracy, complex tasks |
OpenAI text-embedding-3-small | 1536 | Good (0.623 MTEB) | High | Balanced performance, general use |
Cohere embed-english-v3.0 | 1024 | High (0.646 MTEB) | High | Long documents, RAG systems |
all-MiniLM-L6-v2 (Open Source) | 384 | Moderate (0.562 MTEB) | Very High | Fast, low-resource applications |
This table shows that while larger models like text-embedding-3-large offer top-tier accuracy, they also require more resources. Smaller models are faster and more efficient, making them ideal for many real-time applications.
From my own experience, I almost always suggest starting with a lower-dimension, cost-effective model. Build your prototype, run some tests with your actual data, and only consider upgrading to a more powerful (and more expensive) model if you find the search quality isn't hitting the mark. This practical, iterative approach saves you both time and money, letting you focus on perfecting the user experience from the get-go.
Building Your Vector Database With Supabase
Once you’ve turned your content into meaningful vectors, they need a permanent, queryable home. A simple array in your code won't cut it for a real-world application; you need a solid, scalable, and quick vector database. This is where Supabase, powered up by the pgvector extension, really shines. It gives you a strong PostgreSQL foundation that can manage both your typical application data and your vector embeddings all in one place.
Picking a database is a major architectural choice. While there are plenty of options, Supabase delivers an integrated experience that's tough to top, bundling authentication, storage, and database functions together. If you're curious how it stacks up against other platforms, you might find our Supabase vs. Firebase comparison helpful. For our project, its built-in support for vector operations makes it the ideal candidate.
Enabling Vector Capabilities
Getting started is much simpler than you might think. Supabase doesn't have vector support turned on by default, so you'll need to activate the pgvector extension. This is a one-time setup that unlocks all the vector-specific functions and data types you’ll need. You can handle this right from the Supabase dashboard with just a couple of clicks in the database extensions area.
Here’s a peek at the Supabase UI, showing just how easy it is to find and enable pgvector for your project.

This simple action adds a new vector data type to your PostgreSQL instance, which lets you create columns specifically for storing your embeddings. Once that’s done, you’re ready to design a schema that can handle semantic queries.
Designing Your Schema and Choosing a Metric
With pgvector active, you can now set up a table to hold your content and its matching embedding. A standard practice is to create a table with columns for the original text, any useful metadata (like IDs or categories), and, most importantly, the vector itself.
When creating the vector column, you must declare its dimensions. This number must perfectly match the output dimensions of the embedding model you're using. For instance, if you're working with OpenAI’s text-embedding-3-small, the vector column needs to be defined with 1536 dimensions. Any mismatch will throw errors when you try to insert your data.
Next, you need to select a similarity metric. This is the mathematical formula that pgvector will use to figure out how "close" two vectors are. It supports three primary types:
- Cosine Similarity (
<=>): This is the most popular metric for text embeddings. It measures the cosine of the angle between two vectors, focusing only on their orientation, not their length. It's perfect for spotting conceptual similarities, which is why most modern embedding models are optimized for it. - Euclidean Distance (
<->): This calculates the direct, straight-line distance between two vector points. It's a more literal measurement and can be handy in some specific situations, but for text, cosine similarity usually gives better results. - Dot Product (
<#>): This metric takes both the angle and the length of the vectors into account. It can be useful when the magnitude of the vector holds important meaning, but for most semantic search applications, cosine similarity is more intuitive.
My personal recommendation for any project using a modern embedding model is to start with cosine similarity. From my experience, it consistently provides the most relevant results for tasks involving natural language. Now that our database is configured and our schema is planned, we're ready to start loading it with our vectorized content.
Creating Your Search Application That Actually Works
With our database ready and our embedding strategy sorted, it’s time to assemble the pieces into a semantic search application that genuinely works for users. This is where we go from isolated components to an end-to-end system that can gracefully handle real-world questions and deliver results that actually make sense. This part of our guide is less about quick demo code and more about building a solid interface and backend logic you’d feel good about deploying.

Designing a User-Centric Interface
A great semantic search experience begins with the user interface. The main goal is to encourage people to type naturally, almost like they're asking a person a question. This calls for a clean, inviting search bar, free from the clutter of advanced filter options that might nudge them back into a keyword-first way of thinking.
But the UI’s job doesn't end once the user hits "enter." It also needs to provide clear feedback. For instance:
- Loading States: A subtle loading indicator after a query is submitted is a small touch that goes a long way. It reassures the user that the system is on the case and stops them from mashing the search button again.
- No Results Found: One of the most common failings I see in demo apps is a blank screen for zero results. A production-ready app needs a friendly message like, "We couldn't find a match for your search. Try rephrasing your question!" This guides the user instead of leaving them at a dead end.
- Result Display: Results should be presented clearly, highlighting the most relevant snippet of text that matched the query. This context is crucial for helping the user quickly grasp why a particular result was surfaced.
Implementing the Core Search Logic
The heart of our application is the function that orchestrates the entire search process. When a user submits a query, a few things need to happen in a specific sequence.
First, you'll want to do some input preprocessing. Before passing the query to the embedding model, it’s good practice to clean it up. This could be as simple as trimming extra whitespace or even using a model to expand acronyms common to your specific domain.
Next, you generate the query embedding. The user's cleaned query is sent to your chosen AI model (like one from OpenAI) via AnotherWrapper to be converted into a vector. It's vital to wrap this process in solid error handling—API calls can and do fail, and your app shouldn't crash when they do.
Then, you perform the similarity search. The new query vector is sent to your Supabase database. You'll execute a remote procedure call (RPC) that runs a vector similarity search against the embeddings in your table, returning the top 'k' most similar results. Finally, the raw results from the database often need a little post-processing. You might re-rank them based on other factors like how recent the content is or its popularity before sending them back to the frontend.
Bringing all these services together smoothly is key. To effectively create a search application that works, you will likely need to integrate various services, and understanding the best ways to do this can be simplified by exploring some of the top API integration platforms.
Handling Real-World Challenges
Any search system that faces real users will run into tricky edge cases. An ambiguous query like "apple" is a classic example. A good system might return results for both the fruit and the tech company, maybe even categorized for clarity. Handling empty or nonsensical user input (e.g., "asdfghjkl") without throwing an error is also critical for a polished experience.
Performance is another massive consideration. Caching is your best friend here. You can cache the embeddings for popular queries to avoid making redundant API calls, which saves both time and money. This focus on a polished and responsive user experience is what makes users trust and return to your application. It’s the same principle that powers the biggest players online. For example, as of March 2025, the U.S. search engine landscape, which depends heavily on semantic understanding, is dominated by Google with a staggering 86.83% market share. You can read more about the latest search engine market data to see just how critical user experience is.
Making Your Search Fast And Smart
Having a working semantic search application is a huge milestone. But creating an app that feels fast, intelligent, and gets better over time? That’s what turns a cool project into a product people genuinely enjoy using. Once your core search is up and running, it's time to fine-tune it for speed, relevance, and scale. This isn't just about small code tweaks; it's about engineering a system that's both responsive and smart.
Beyond Basic Similarity Ranking
Right now, your search results are probably ranked by cosine similarity—a measure of how close a query vector is to the document vectors. It's a solid starting point, but true relevance has more layers. A smarter system uses other signals to re-rank the initial results and deliver what the user is really looking for.
Here are a few factors you can incorporate:
- Content Freshness: If you're building a news app or a blog, a result from yesterday is almost always more valuable than a similar one from last year. You can implement a time-decay function in your ranking algorithm to give recent content a boost.
- User Engagement: Pay attention to what users click on. This data is pure gold. If people consistently pick the third result for a specific query, your system should learn from that behavior and start promoting that result in future searches for the same or similar queries.
- Business Logic: An e-commerce site might want to feature products that are on sale or have plenty of stock. You can blend these business rules with the semantic score to create a final ranking that serves both the user's intent and your business goals.
Keeping Your Application Snappy and Scalable
As your application gains traction, your dataset will grow and so will the number of queries. Both can bog down your search performance if you haven't planned ahead. Let's dig into some practical ways to keep things running smoothly.
Intelligent Caching and Database Optimization
Calling an embedding model's API costs you both time and money. A straightforward yet powerful optimization is to cache query embeddings. Think about it: if ten different users search for "how to reset my password," there's no reason to generate a new vector each time. You can store the query and its vector in a high-speed cache like Redis. Before hitting the API for any new search, your application should first check the cache.
On the database front, good indexing is essential. While we've already set up a basic index, Supabase's pgvector extension allows for some advanced tuning. For example, the index_options for your vector index, such as m (the number of graph connections) and ef_construction (the number of neighbors considered during indexing), directly affect the balance between search speed and accuracy.
Tweaking these values is a trade-off. Increasing them can lead to better recall (finding more relevant results) but will make indexing slower and consume more memory. My advice is to start with the default settings and then run A/B tests to see how adjustments impact performance. This data-first approach will help you find the optimal configuration for your specific application, ensuring your search stays fast without becoming too expensive to run.
Advanced Features And Production Reality
Getting your semantic search application up and running is a great first step, but it's really just the starting line. To build an experience that people genuinely find useful, you need to go beyond basic retrieval and think about what it takes to run this in a real-world, production setting. This is where we separate a simple semantic search tutorial from a production-grade system.
Pushing Beyond Standard Search
A truly effective system doesn't just answer queries; it anticipates user needs and can handle more than just plain text. Think about adding features that provide some serious value:
- Multi-modal Search: Imagine your users searching an image library with a text query like, "a sunny day at the beach with a red umbrella." This is possible by using models that can create embeddings for both text and images, letting you store and compare them in the same vector space.
- Personalization: You can make search results feel more relevant by creating user profiles based on their search history and what they click on. By giving a small boost to results that match a user's known interests, the search experience becomes much more personal and effective.
- Real-time Suggestions: As someone starts typing, you can run quick, preemptive searches to suggest popular queries or even show direct results. This helps guide them to better answers and makes the whole process feel smoother.
The Realities of Production and Maintenance
Running a semantic search system in the wild comes with its own set of challenges that need careful planning. Ongoing maintenance isn't something you can tack on later; it's a fundamental part of the application's lifecycle. It's a good idea to think through your deployment strategy from the start. If you're looking for practical advice on this, we've covered it in our guide to AI model deployment.
Here are some key operational tasks you'll need to manage:
- Updating Embeddings: Your content changes. When new items are added or existing ones are modified, you need a way to generate and insert new embeddings. A common way to handle this is by using database triggers or a message queue to automatically kick off the embedding process.
- Model Versioning: The AI models we rely on are always getting better. You'll need a solid plan for testing new model versions and migrating your existing embeddings without disrupting your service.
- Monitoring and Fallbacks: What’s your plan if your embedding provider's API goes down? A resilient system should have a fallback, like temporarily switching to a traditional keyword search, while it alerts your team about the problem.
Ready to build these advanced features and more without the headache of starting from scratch? AnotherWrapper gives you the complete toolkit to launch AI-powered applications, including production-ready search, in a fraction of the time. Get started with AnotherWrapper today!
Stay ahead of the curve
Weekly insights on AI tools, comparisons, and developer strategies.

Fekri
Building tools for the next generation of AI-powered startups. Sharing what I learn along the way.
Related
Tags
Continue reading
You might also enjoy

Agile Release Management: Your Complete Guide to Success
Master agile release management with proven strategies that work. Learn from successful teams who've transformed their software delivery process.

AI Model Deployment: Expert Strategies to Deploy Successfully
Learn essential AI model deployment techniques from industry experts. Discover proven methods to deploy your AI models efficiently and confidently.

AI MVP Development: Build Smarter & Launch Faster
Learn top strategies for AI MVP development to speed up your product launch and outperform competitors. Start building smarter today!